

Tani jeni duke ndjekur
Gabim duke ndjekur përdoruesin.
Ky përdorues nuk lejon përdoruesit për ta ndjekur atë.
Ju jeni ndjekës i këtij përdoruesi.
Plani juaj i anëtarësimit lejon vetëm 0 ndjekje. Përmirësoni planin këtu.
U anulua me sukses
Gabim duke çndjekur përdoruesin.
Ju e keni rekomanduar përdoruesin me sukses
Gabim në rekomandimin e përdoruesit.
Diçka shkoi keq. Rifresko faqen dhe provo sërish.
Emaili u verifikua me sukses.

medak,
india
Aktualisht është 10:15 m.d. këtu
U bashkua shkurt 11, 2014
0
Rekomandime
Gopi A.
@gopiande
3,5
3,5
97%
97%
medak,
india
96%
Punët e Plotësuara
100%
Brenda Buxhetit
98%
Në Kohë
7%
Shpeshtësia e Rimarrjes në Punë
Multi Talented Professional
Kontaktoni Gopi A. për punën tuaj
Identifikohu për të diskutuar çdo detaj gjatë bisedës.
Portfolio
Portfolio
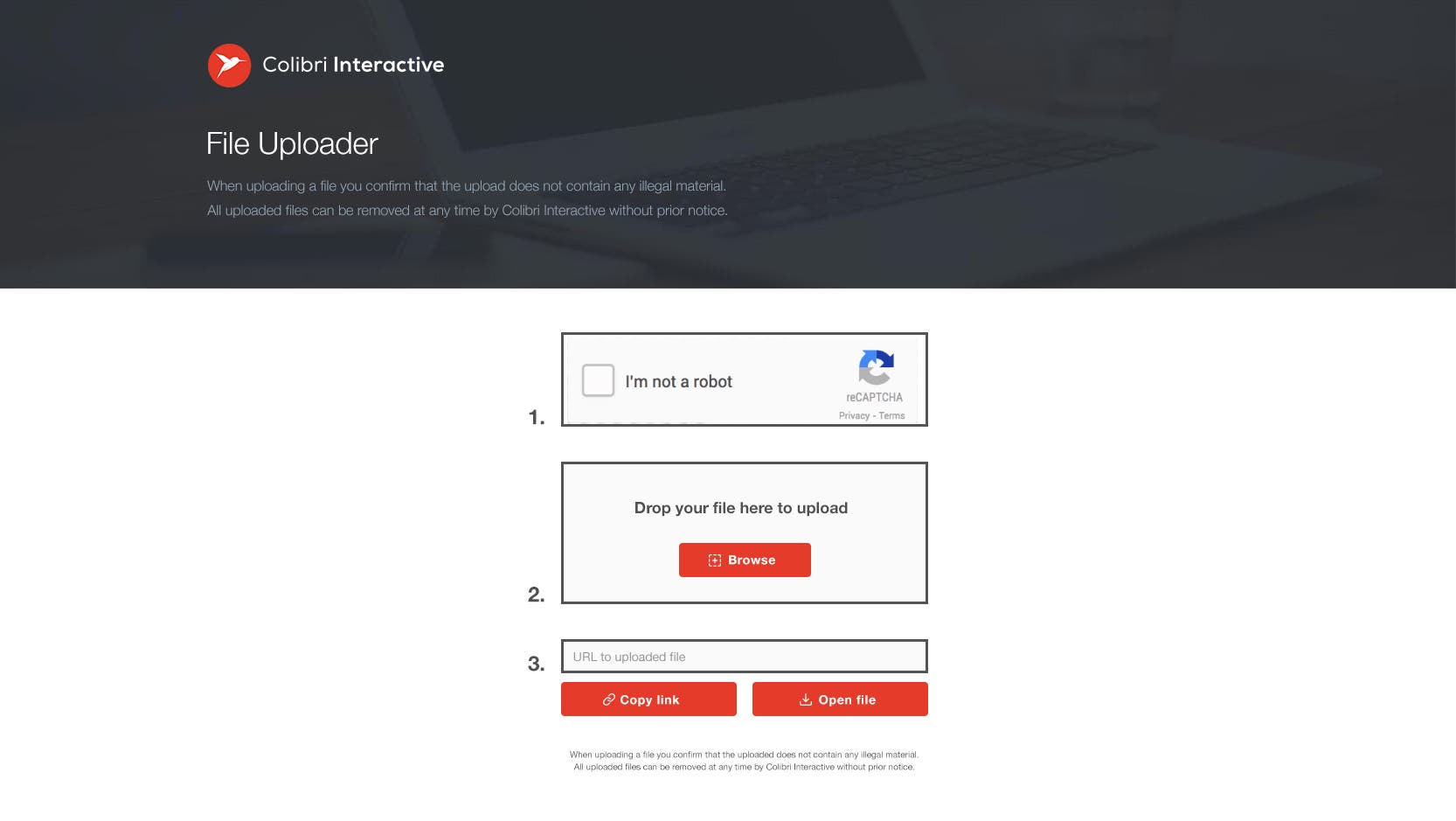

Simple Uploader Webpage
File transfer App in python
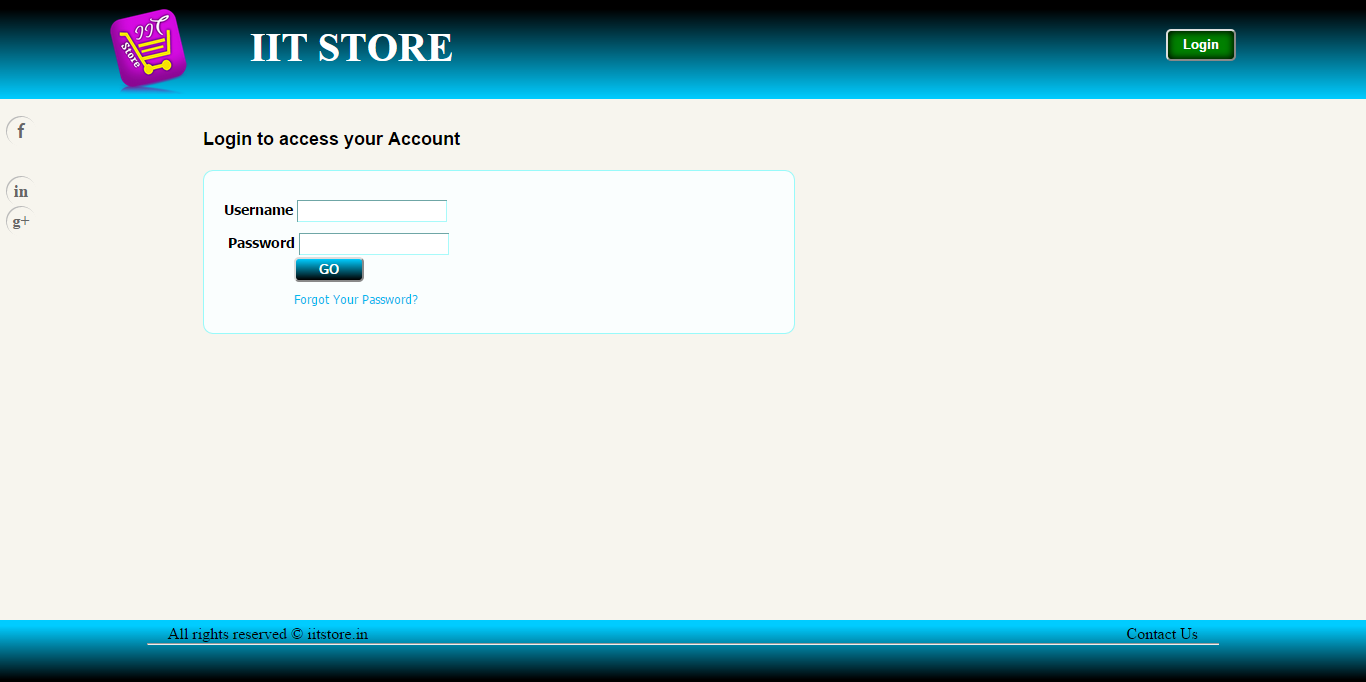

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Database Site for IITStore.in

Basic Graph Editor Using Canavas in HTML5
Simple Uploader Webpage
File transfer App in python
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Database Site for IITStore.in
Basic Graph Editor Using Canavas in HTML5
Vlerësimet
Ndryshimet u ruajtën
Duke shfaqur 1 - 5 nga 23 përshtypje

$40,00 USD
JavaScript
K

•
$15,00 USD
Python
Software Architecture

•
₹900,00 INR
PHP
Website Design
Graphic Design
HTML
S
•

Përvoja
Internship
maj 2015 - korr 2015 (2 months, 1 day)
Created USB driver for AplxPlus Technology's own hardware electronic board. The driver is written using LibUsbJava.
Arsimi
B.Tech
(4 years)
Kualifikimet
Machine Learning by Stanford University
Coursera
2017
Machine Learning by Stanford University on Coursera. Certificate earned on September 2, 2017
Kontaktoni Gopi A. për punën tuaj
Identifikohu për të diskutuar çdo detaj gjatë bisedës.
Verifikimet
Dёshmitё
Kërko punonjës të pavarur të ngjashëm
Shfleto ekspozita të ngjashme
Ftesa u dërgua me sukses!
Faleminderit! Ne ju kemi dërguar me email një lidhje për të kërkuar kredinë tuaj falas.
Ndodhi një gabim gjatë dërgimit të email-it tuaj. Ju lutemi provoni përsëri.
Kopja te kujtesa e fragmenteve nuk u krye, provo sërish pasi të kesh përshtatur lejet.
U kopjua në tabelë
Po ngarkohet shikimi paraprak
Leja u dha për Geolocation.
Seanca e hyrjes ka skaduar dhe ke dalë. Hyr sërish.